Checklist to evaluate MPC deployments
This is a quick checklist I use when evaluating multi-party computation designs, deployments or ideas; both in industry and academia. I hope you find it useful. Two qualifiers:
- While this was written mainly thinking about MPC, most of the following applies also to any fancy cryptographic technique.
- Different scenarios call for different criteria. So do not take this checklist literally, but rather as an aid in your assessment process.
Assumptions #
Have you documented all implicit and explicit assumptions? Good results are just implications: if some hypothesis hold, then you can do some fancy stuff. This doesn’t necessarily mean the initial assumptions hold in your particular application. Examples of common assumptions that may not hold in your case:
-
Trusted hardware does / does not exist. Beware of assumptions of the style “can’t use secure hardware” since that will artificially constrain your design space.
-
Trusted third parties are / aren’t acceptable. Don’t your customers need to trust you anyways? To what extent? For what is it OK for them to trust you? For what not? And what about a third party? How do you explain this? Pinky promise or cryptography? This analysis can be nuanced.
Implicit/tacit assumptions are all over papers. The most fundamental assumptions will certainly not appear in a research paper. For example: in a new, fancy threshold signature paper you won’t find the basic assumption that threshold signatures are useful when naive multi-signatures (multiple parties sign independently the same message) are unacceptable.
Sensitivity #
What is the sensitivity of data you’re handling? Are you handling…
- … other people’s personal information? Other people’s health data? Other people’s money?
- … or, in contrast, are you handling other people’s emojis? Likes on cat pictures?
Those two categories have very different risk appetite profiles. You get the idea.
What is your rigor level needed? Determine this based on the nature of your data. Would you be comfortable explaining your design decisions after something goes wrong? Also, consider the person writing the paper has a very different risk profile than the person deploying to production. The #1 goal for The Person Writing The Paper is getting it published in a good conference. The potential downside is negligible for them.
Maturity #
Does the scheme maturity match your data sensitivity? Loosing other people’s money has a very different impact than leaking what’s the preferred emoji of English-speaking iPhone users. You can probably run cutting-edge stuff in the latter problem.
Evaluating a technology maturity isn’t easy. Here are some tips:
- Peer review means peer review and nothing more. Not exhaustive audit, not comprehensive review. Peer review often means an expert reviewing the content for couple of hours.
- Test of time can be meaningful or meaningless. For example: Rainbow signatures were a well-studied promising scheme, designed in 2004 and broken 18 years later by the fresh eyes of a 20-something-old fresh out of grad school. Take-away: it’s difficult to predict when the next Perelman will emerge from a cave and tell us how to quickly factor integers. We always live with this risk.
- Proofs can be flawed. Provable security is a contentious topic. I personally like provable security to the extent that signals that someone had to think a bit on the scheme. Recommended the excellent series on another look on provable security.
- Good and garbage conferences look identical from the outside. You need to become an expert to tell them apart. Besides, “unpublished” works can also be groundbreaking.
- Twitter. It is easy to mistake popularity for maturity. For example, contrast the popularity of ARX designs with the opinion of the Keccak team on the topic:
… It is very hard to estimate the security of [ARX] primitives. […] For MD5, it took almost 15 years to be broken while the collision attacks that have finally been found can be mounted almost by hand. For SHA-1, it took 10 years to convert the theoretical attacks of around 2006 into a real collision. More recently, at the FSE 2017 conference in Tokyo, some attacks on Salsa and ChaCha were presented, which in retrospect look trivial but that remained undiscovered for many years.
Alternatives #
Reevaluate the alternative, consider the naive multiple-party extension. For example, let’s say we’re evaluating whether to use a threshold signing scheme or not. &Sometimes, the straight alternative, multi-signatures (naively signing multiple times with different keys) work natively at the protocol level. This is the best case. Sometimes you can define the protocol to accept multi-signatures (for example when you are writing the firmware verification routine). The naive multi-party extension is often way waaaaaay less complex and easier to get it right than the complex MPC protocol.
Cryptography is tricky to get it right, consider the alternative where all the resources diverted to MPC were instead allocated to build a more traditional security system safe. What would you build?
If this sounds obvious to you (it is!), you’d be surprised with the staggering amount of “MPC for the sake of MPC” where the naive alternative would work just fine (but probably less useful to raise money).
Design space #
Do you know what you design space is? For example: can you use secure hardware? Why not? Using secure hardware typically leads to simpler and better systems. Sometimes you just can’t use them (cost, development or accessibility problems – maybe your customers don’t have an expensive phone with a separate enclave). Sometimes you do and can afford to give a piece of hardware with a security enclave. There’s an incredible amount of secure hardware: smart-cards, yubikeys, Apple secure elements, AWS Nitro enclaves. Try to use them.
Naturally, the more restrictive your assumptions are the more complex your end design will be. And beware of security nihilism: you better trust something, typically some hardware. You need to bootstrap trust somewhere – no amount of cryptography will help you pull trust out of a hat.
Environment #
Does your deployment environment match the security assumptions? A basic assumption in MPC is that the effort to compromise N parties is some function of N. If all parties are being deployed to the same environment, this assumption is broken: the cost to attack N parties (over the network) is the cost of a single attack, plus a bit of copy-paste to replicate the attack to other parties.
This copy-paste problem appears for example when the same software is deployed in several regions in AWS, possibly managed by the same team, and running the same tech stack.
For MPC to make sense, it should be deployed into an heterogeneous environment. There are fields which do this, for example aeronautics. However, this is very expensive. Triple-modular redundancy yields very safe designs, but at a very high cost.
What are the single points of security failure? Abstractions are made to make our lives easier. There is an huge amount of details left out in written publications. Make a list of them. For example: how does code get distributed to your endpoints?
How does the recovery flow look like? In any moderately complex system, you’ll have a recovery flow: reconstruct your key material from backups, or send the user a link to reset their password in case they forget it. Recovery flows are a juicy target for attackers. Analyze hard the recovery flow, do the MPC properties also extend to the recovery flow?
Wrong tool? #
Sometimes, MPC is just the wrong tool for the problem. Examples:
- sometimes MPC is trying to solve a UX problem at the core
- other times, MPC tries to retrofit new functionality into a legacy system
- cryptocurrencies have spun lots of interesting applications of MPC. Think: did this problem exist before cryptocurrencies? How were we solving it before? is it relevant today?
Sustainability #
Does your team have the necessary competences to successfully maintain your MPC system throughout the entire lifecycle? One thing is translating an algorithm from a paper into code (that’s the easy part), the hardest part is maintaining that and having assurance it’s doing the right thing. For example: in order to write unit test of any MPC scheme you need to understand the scheme at a very deep level. Take for example this apparently innocuous bug in a Threshold RSA signing scheme.
Ecosystem #
Is this system deployed somewhere else? Should you care? The fact that company X did it doesn’t mean you should do it. Maybe they are 20x your size, maybe they have 20x your budget, maybe they are geniuses, maybe they are clueless, maybe they did it to retain a key employee, maybe their product manager didn’t follow this checklist :-)
Apple does differential privacy. Apple has big pockets. They can afford to hire a team of very competent researchers and throw this problem at them to play with. But differential privacy is insanely complex – I know talented people that gave up on doing research on this field because it is so so hard. Apple does it, that doesn’t mean you can spark the magic dust of differential privacy everywhere.
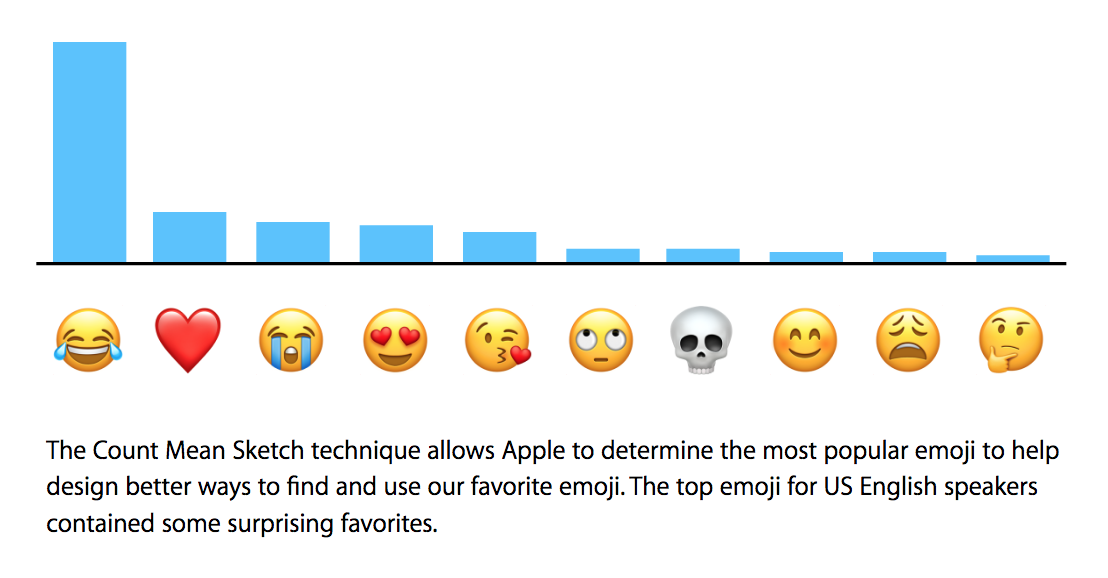
Doing MPC just for marketing is very, very expensive. You better spend it elsewhere!
Complexity #
Ultimately, is the complexity warranted, when all things are considered? Complexity is the elephant in the room in contemporary cryptography. At the end of the day, this is the tricky question – all things considered can take many forms. Good luck!